COMPUTER
COMPUTERInterfaces & The Mind: An Introduction
I was at a get-together recently when someone dropped the question: “so what do you do?” I paused for a bit before revealing that I design software – half to gather my thoughts and half to take one last sip of my drink before the unavoidable follow-up questions. Software design? Do you make icons and stuff? Do you have to be really good at computers?
I spent a few minutes talking about how I work with people to identify problems, come up with features, apply psychological principles to make intuitive interfaces, and so on. It’s very well rehearsed by now and always tends to leave people with a very intrigued look on their face. A few minutes later, my new friend insisted on introducing me to a few friends. We walked over, shook some hands. She then went on to introduce me as her “new programmer friend.” So much for that.
Software design is a misunderstood field. And rightfully so. It’s relatively new, it’s a niche inside a niche, and it’s highly multidisciplinary. You can’t really go to school to major in software design. The software designer is sorely missing from the typical lineup of firemen, scientists, and doctors in children’s literature, so it’s no surprise that people simply remember ‘programmer’ – they have no prior schema to relate it to.
This multi-part series of posts intends to introduce software design from a slightly more approachable angle – that of psychology. In the posts to come, I’ll be talking about how things like working memory, visual attention, and other brain processes affect the way we make sense of and interact with software interfaces.
From Stovetops to Tablets
Let’s start with something that has nothing to do with software. Look at these two stove top designs.
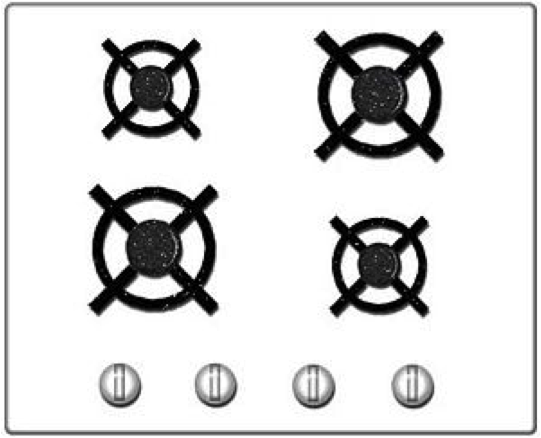
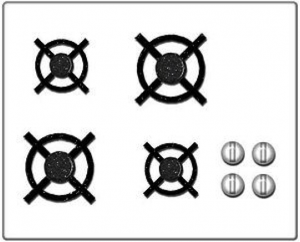
Which one would you prefer to own? Price and other factors aside, the one on the right is clearly easier to use due to what’s called a ‘natural mapping’. There is a clear analogy between the square configuration of knobs and the square configuration of burners, so turning on a specific burner is much easier. Now take a look at the computer interfaces below.
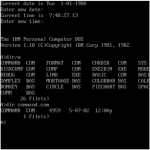
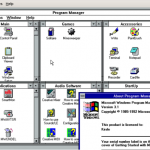
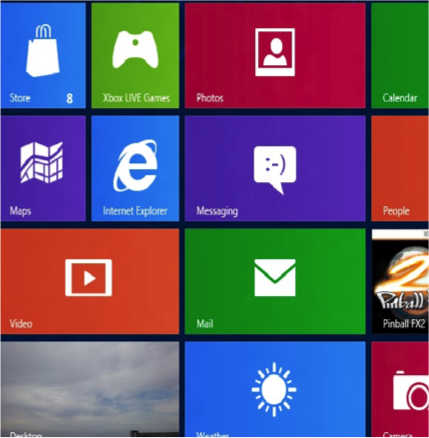
These should be somewhat familiar. They represent the progression of user interface technologies over the last thirty or so years. And there’s an analogy here: just like each of the two stove interfaces above allowed a user to identify a burner and activate it, each of these interfaces allows someone to identify a program and start it up. Certainly there have been some major leaps forward in stovetop and computer design. Each one is a little easier to use than the last. The interesting thing is that the key to improvement in both cases was lessening the gulf of representations. You could say that the ‘better’ interfaces – whether stove or screen – required people to jump through fewer associative hoops. To do less translating from one mental concept to another. All of which ultimately lessens the burden on working memory.
The first, more awkward, stovetop interface has you jump through (at least) two associative hoops. First of all, you have associate a plastic knob with a burner and the act of turning it with the concept of starting a fire. It’s obvious today, but if you were to bring along a time traveler from the 18th century and stand him in front of the stove, their first instinct would likely involve touching the burners themselves. Second, and more relevant, you have to associate a line of knobs with a square of burners. Likewise, with the first command line interfaces, turning on a program involved a few steps of implicit mental acrobatics. First you had to identify a program – for which you had to decode a line of text (often cut off, often involving a cryptic suffix like ‘exe’ or ‘bat’). Once you had identified the program, you had to translate the action of ‘opening’ into a phrase involving words like ‘cd’ (which you mostly had to memorize). Finally, once you had the proper phrase in mind, you had to translate that sequence of letters into keystrokes on a keyboard that (somewhat arbitrarily) threw the alphabet into a relatively unintuitive configuration. The Windows 3.1 interface eliminated a few of these problems by allowing you to see pictures, which the visual system has an easier time parsing quickly, and by allowing you to do something akin to ‘pointing’ with your hand – something almost innately familiar. I’m talking about the mouse, of course. If you’ve ever watched an elderly person use a mouse, you’ve seen that it’s really not that easy. Sure, the directional mapping is somewhat natural – up is up, down is down, and so on, but you still have to develop a sixth sense for how the speed of the mouse relates to the speed of the cursor. It’s almost like learning to work with your fingers under a microscope. Finally, touch interfaces came along and eliminated that associative gap too. In the picture on the right of the Windows 8 interface, you identify an object using a large, prominent visual representation and then manipulate it by reaching over and touching. Just like in real life.
The point here is that the same mental processes and constraints that apply to our understanding and manipulation of every day objects like stoves (or doors, or signs, or even people) apply to computer interfaces as well. Computers are just the next generation of tools and environments that we, as humans, have begun to interact with. One of the principal challenges of a software designer is to design tools in a way that takes into account human psychology – whether it’s hard-wired such as motion detection in peripheral vision or commonly learned associations like the tendency to read from left to right or to assume that a mouse cursor in the shape of a hand implies interactivity.
In the same way that an architect elicits emotions like pride through certain materials and large spaces, or that a film director draws attention to an important detail by briefly cutting to the knife behind the murderer’s back, a software designer in many ways curates human attention as we experience and explore virtual environments.
This is by all accounts only one part of software design. I’ve left out any mention of the user research process, teasing apart implementation ideas from fundamental needs, understanding context, validation, aesthetics, and a host of other important things – but this, to me, is the fundamental and unique thing that design brings to software. This is the angle that makes software design approachable and relatable to people outside (and even inside) the world of technology – distinguishing it from pretty pictures, from programming, and from business concerns.
In the next part of this series, I’ll delve into working memory and some of the ways that it can be applied to software design.